How We Trained Neural Network to Count People for AI-Powered Transportation, Retail, & Smart Cities


Deep learning boosts productivity and reduces costs in various business applications. In this article, we will show how our engineers created a neural network for human counting. This solution can now be applied to public transport, smart buildings, retail and queue management.
Table of contents
Where neural networks are used
How head & face detection systems work
How the neural network is trained
Fine tuning deep learning model with iterative dataset
Deep learning is a type of machine learning in which neural networks are trained on large amounts of data. This technology allows for automating complex business processes and implementing analytics for data-driven decisions in various areas.
Over the past 5 years, the deep learning market has grown almost 22(!) times. At the end of 2022, it was estimated at USD 49.6 billion.
Where neural networks are used
Before the introduction of neural networks, human counting tasks were solved with the help of a human operator and surveillance cameras, as well as optical sensors in turnstiles (where available). Computer vision and deep learning technologies simplify and automate this process in many areas:

Public Transporation. People counting solutions help control passenger traffic, analyse rush hours and traffic congestion. Using analytics data, city authorities can optimise public transport schedules: shorten intervals between vehicles, add extra trips on the route, etc.

Smart Building. AI-based cameras make it easier to operate and maintain buildings. Here are just a few scenarios on how to apply machine learning for smart buildings:
- monitor the capacity of office space and meeting rooms in a hybrid work or co-working format;
- count people and monitor occupancy and social distancing;
- adjust heating, air-conditioning and lighting systems according to needs;
- monitor lift occupancy and avoid overloading.
Retail. Machine learning in retail analytics optimises staff workloads. The data obtained helps to study customer interest in products and displays, capture the trajectory of people moving through the sales floor and change the shop design: placing sections in a convenient sequence or favouring promotional materials.
Queue Management. Head recognition cameras help manage queues at airports, train stations and big shops by recording the number of people in the line and their waiting time. If the data shows that the queue is growing quickly and moving slowly, it is a signal to open additional check-in counters, cashiers, or call staff.
City Mobility. Smart cameras for video surveillance make the urban environment accessible for people with disabilities or parents with prams. Such cameras on public transport help drivers identify passengers who need assistance: a ramp to get down or a mechanical lift.
How head & face detection systems work

Let's look at how a neural network works when paired with a camera. This combination is used in most video surveillance solutions. Previously, we described how this works in our case study on a smart bike parking with the SONY Spresense AI camera.
Here are the key steps in the process of counting objects in the camera video:
- Capture images from CCTV, IP, or specialised sensors covering the target area.
- Improve image quality: filtering, noise reduction, stabilisation and clarity of images or video frames.
- Detect objects using computer vision algorithms, including single-shot detection (SSD).
- Count objects and analyse their characteristics: crowd density, queue time, flow patterns, etc.
- Integrate and visualise data: display dashboards and transfer to control systems and applications.
For such a system to work properly, the neural network must be trained; it is a complex but very exciting process, which we describe below. Now, Promwad engineers train a neural network for face and head detection within an ongoing machine learning project in the automotive industry.
How the neural network is trained
Head detection is a subset of object detection tasks. Why is it important to identify the head? In a number of applications it is not sufficient or possible to identify the presence of a person. A person's figure may be partially hidden in a crowd or the camera may be filming a crowd from above or from the side.

A neural network trained to recognise heads and faces. Video source: "Stable multi-target tracking in real-time surveillance video" by Benfold, Ben and Reid, I. CVPR 2011
To count people, a neural network must do several things:
- detect the presence of a person in the frame;
- find the area where the head is located;
- determine the coordinates of the frame surrounding the head;
- assign an identifier to the object so that it can be tracked from frame to frame.
We will use SSD object detection architecture – one of the popular algorithms.
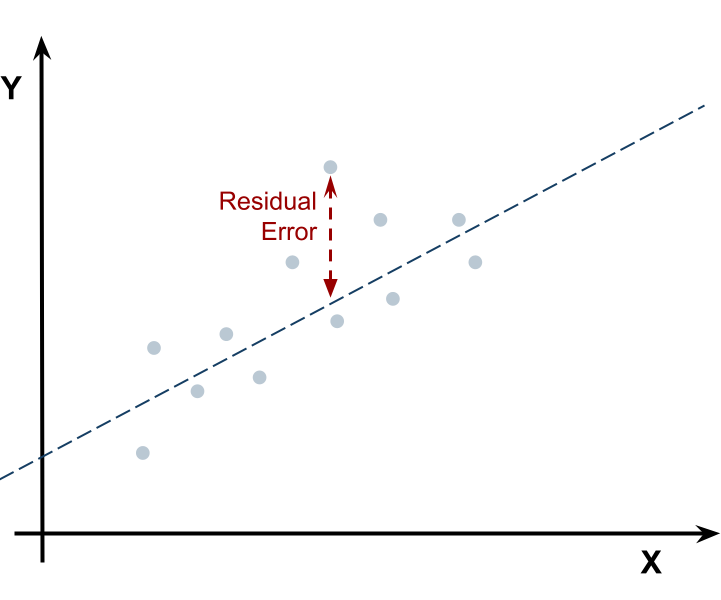
The simplest case of a loss function in machine learning
Fine tuning deep learning model with iterative dataset increasing for face counting
When training a neural network, we face two important interrelated issues:
- Where and how many images to take for our training in order to achieve acceptable accuracy of the neural network;
- How many iterations should be done for the neural network to learn sufficiently.
The learning time and accuracy of the algorithm depends on how these problems are solved.
We have chosen an iterative approach to train the neural network, loading a new portion of images at each iteration. This approach solves a potential performance problem with the platform where the model is trained: we pick up more data and iteratively extend the existing dataset. The cycle "ensuring model performance → expanding the dataset → fine-tuning the model" is repeated until we get a good result.
Training our neural network took 7 iterations. In the zero iteration, we trained the model on a dataset from free sources . It consisted of 2405 images that illustrated heads and faces with different characteristics: angle, size, and density.

Images from a free dataset are used to train the model for zero iteration. Source: github.com
We continued training and loading new portions of photos. We got an accuracy result of ~ 92% at the sixth iteration and stopped there. The further the learning process goes, the smaller the increase in accuracy it gives. In some cases, the model shows more accurate results with each iteration, but the performance decreases at the next iteration. It happens because of internal failures or because the wrong inputs were loaded.
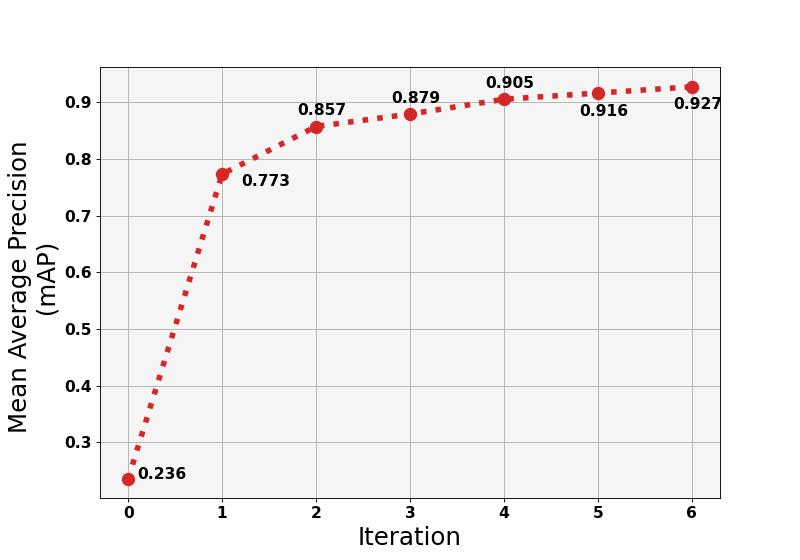
Iteration diagram of our neuro network training for people counting
When we train a model in iterations, we, on the one hand, extend the data on which it is trained. On the other hand, we control the accuracy and can predict the number of additional iterations.
We have created a service for iterative learning of our neuromodel, which includes several open source services and tools. Our iterative process involves several steps:
- Training process monitoring. With a specialist service we can log different metrics such as loss, map, etc. – this is how we understand the model's behaviour in the training process.
- Inference on new data. At this stage, we make predictions (output) on the newly selected data. Predictions in Common Objects in Context (COCO) format are needed for future annotation – creating truth bounding boxes. This procedure significantly reduces the time since the annotation process is one of the most time-consuming in machine learning.
- Annotations refinement. After the output, we have a file with predictions of values for the heads in the new batch of data. These predictions need to be refined because the models are not perfect. We load this file into Computer Vision Annotation Tool (CVAT) and manually refine the predictions.
As a result, we have a neuro model that detects faces and heads from different angles with 92% accuracy, which can be used in surveillance systems in public places, airports, train stations, large transportation hubs and retail analytics. We are ready to use this solution for your business, adapt it to the specific task and bring the recognition accuracy to the required level.
* * *
Human counting solutions help improve security in buildings and crowded areas. Based on deep learning algorithms, these solutions provide reliable and accurate results in real-time, even in complex scenarios.
Advances in technology and the development of more sophisticated sensors will encourage companies to develop face recognition software and conduct accurate training of neural networks. More efficient and intelligent systems will be created that meet the needs of business and society.
As a company specialising in machine learning development, we offer clients services, from consulting to developing business-specific solutions. Contact us, and we will tell you how our engineers can develop a people-counting solution tailored to your business.
Our Case Studies for Smart Cities






