2026 Engineering Playbook for Broadcast & Media: ST 2110, Latency Budgets, and Live Workflow Validation


Head of Broadcasting & Telecom at Promwad
As broadcast and ProAV ecosystems move further into IP, cloud, and AI-assisted workflows, the competitive advantage for OEMs is shifting. It’s no longer enough to ship “a box that supports 4K.” Winning platforms in 2026 are defined by interoperability (ST 2110 + NMOS), measurable latency budgets, and software-defined video pipelines that can evolve after deployment.
Ahead of ISE 2026 at Fira de Barcelona Gran Via, I want to share seven engineering trends I expect to dominate customer requirements—and to outline what they mean for broadcast equipment development roadmaps.
At Promwad, we support broadcasting OEMs and operators with full-cycle embedded systems development—from architecture and prototyping to verification and production support—backed by 20+ years of experience and a 100+ engineer team.
We’ll help you identify the fastest path to SMPTE 2110 integration, lower latency, and AI-ready pipelines.
1. TL;DR: 7 trends in 7 lines (and what they mean for OEMs)
- Cloud-native broadcasting & REMI → your devices must behave like managed IP nodes, not isolated appliances.
- ST 2110 + NMOS by default → interoperability becomes a product feature (and a commissioning risk if you ignore it).
- Ultra-low latency as a system requirement → latency budgets, not “best effort,” especially for live and interactive use cases.
- AI-first production → automation shifts from “nice-to-have” to default workflow layer.
- Vertical video for live & VOD → multi-aspect pipelines and auto-reframing move into professional production.
- OTT/FAST keeps growing → ad-ready delivery + analytics hooks become mandatory across devices and apps.
- Trusted media & deepfake protection → provenance and security move into broadcast engineering requirements.
2. The 3 bets to build around
1. Cloud-native + IP production (REMI is a consequence, not a feature)
Cloud playout, distributed editing, remote monitoring, and hybrid production aren’t separate “cloud projects” anymore—they are the operating model. For OEMs, this changes what customers expect from your hardware and software:
- Your device becomes a managed component in a larger IP system (observability, remote lifecycle, predictable updates).
- Resilience is not optional: failover behavior and real-time visibility matter as much as raw throughput.
- Interoperability drives purchasing decisions: integrators want commissioning predictability, not vendor lock-in.
From an engineering standpoint, this is where SMPTE ST 2110 integration becomes the backbone. SDI-to-IP migration is rarely a “lift-and-shift”; it is a controlled transformation where you must maintain on-air stability while transitioning signal transport, timing, and device discovery/control.
What this means for OEM roadmaps in 2026:
- Build an SDI→IP strategy that supports coexistence, not only “final state.”
- Treat NMOS as a first-class capability for discovery, connection management, and predictable integration.
- Validate end-to-end behavior under realistic load—timing, jitter, packet loss, and failover—not just lab demos.
How we can help you drive this trend: seamless SDI-to-IP migration, ST 2110 + NMOS integration, performance validation, and commissioning-focused interoperability engineering.

Case in Brief: High-Speed OpenGear SDI-to-IP Сards (Multi-Camera)
For a European streaming operator, we developed FPGA-based OpenGear cards converting 8× 4K120 SDI streams to IP under SMPTE 2110, plus a high-bandwidth 10Gb NAS subsystem for real-time multi-camera workflows. This is the kind of “IP + performance + storage” architecture OEMs are increasingly asked to deliver as an integrated platform, not as separate boxes.
Read full case study: High-Speed OpenGear SDI-to-IP Cards for Multi-Camera Broadcasting
2. Ultra-low latency becomes product-critical (live, sports, interactive)
Latency used to be “a number” on the spec sheet. Now it’s a customer experience requirement—and a differentiator for OEMs building contribution, production, monitoring, and live distribution systems.
The trap: trying to fix latency late in the program. In modern IP pipelines, latency is a system property driven by choices across the entire chain:
- packet I/O and buffering strategy
- CPU/GPU/FPGA pipeline topology
- synchronization and timing boundaries
- protocol choices and acceleration layers
This is why we start with a defined latency budget and verify it end-to-end—under realistic load—before optimizing selectively. In practice, performance layers like DPDK or NVIDIA Rivermax can be the difference between “works in the lab” and “works in production at scale.”
A practical OEM playbook for 2026:
- Measure first: instrument latency per stage (ingest → processing → transport → output).
- Design for zero surprises: avoid hidden buffering; document what adds frames.
- Pick the right acceleration point: not everything needs “maximum performance,” but your bottleneck must be intentional.
- Prove resilience: latency under stress (packet loss, failover, noisy networks) matters more than ideal-case numbers.
Where 5G fits in this story: 5G broadcast and ultra-low latency delivery will keep moving from pilots toward commercialization. For OEMs, the important takeaway is less the radio standard and more the engineering discipline: latency, power, and transport efficiency will be evaluated together—especially for mass events and live sports.
How we can help you drive this trend: ensure ultra-low-latency IP transport for live broadcast with Nvidia Rivermax and DPDK.
3. AI-first production & AI video analytics
AI in broadcast is quickly moving from “experimental features” to the default production layer—especially in analytics, compliance, and quality control. For OEMs, the strategic shift is clear: customers want systems that reduce manual workload without compromising reliability.
The engineering question isn’t “Do we use AI?” It’s:
- Where does AI run? Edge/on-prem/cloud depending on latency, cost, and privacy.
- How do we trust AI output? Confidence scoring, explainability, human-in-the-loop controls.
- How do we operationalize it? Monitoring, retraining pipelines, and versioning.
This is where AI video analytics becomes a practical, shippable capability: automated scene/object/quality analysis that reduces operator routine across mixed-vendor ecosystems—from contribution to playout and monitoring.
How we can help you drive this trend: AI-powered content analytics embedded directly into your video pipeline—covering media content categorisation, advertisement filtering and personalisation, precise content segment retrieval and analysis, and sports analytics.

Case in Brief: Next-Gen Portable Live Streaming Device
We upgraded a professional portable broadcast device with four LTE modems, additional HDMI/USB interfaces, a touchscreen UI, smart framing, and OTA software updates.
A new battery increased runtime to 8 hours, supporting real-world live coverage needs. The client planned the first batch of 1,000 units—a good example of how AI-assisted features and updateability must be engineered into mass-produced devices, not bolted on later.
Read full case study: Next-Gen Portable Live Streaming Device for Professional Broadcasting
4 more trends you can’t ignore
Vertical video for live & VOD (professional workflows go multi-aspect)
Vertical is no longer “social-only.” Live sports, concerts, and events increasingly require multi-aspect outputs with automatic reframing and synchronized multi-camera workflows.
For OEMs, the product requirement is clear: support for multi-aspect encoding, metadata-driven framing, and predictable real-time performance—especially in portable and field-ready devices.
Our portable streaming device upgrade mentioned above (smart framing + OTA + multi-modem connectivity) is a good example of how these requirements show up in real products.
OTT & FAST dominate viewing (monetization stacks become engineering requirements)
For OEMs building gateways, STBs, CTV devices, or enabling SDKs, OTT is no longer “someone else’s app.” Ad-ready delivery, analytics, and consistent playback behavior become part of the platform contract.
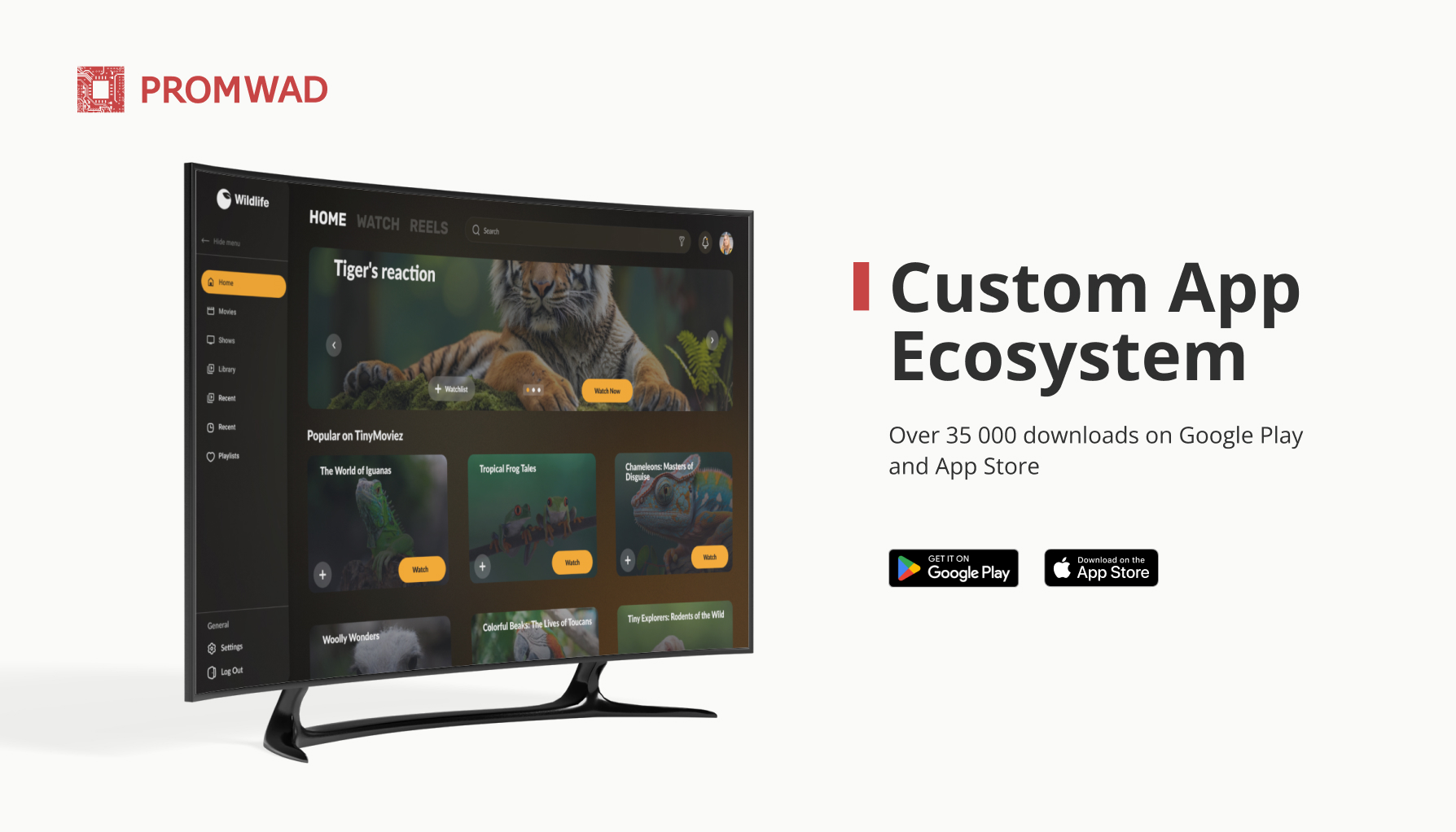
Case in Brief: WildTV Ecosystem (Android TV + Mobile Apps)
We delivered a white-label ecosystem (Android TV, iOS, Android) and the result improved monetization: 35,000+ downloads and 20% trial-to-paid conversion. For OEMs, this translates into practical requirements: observability, DRM-ready integration points, and performance stability at scale.
Read full case study: Android TV Platform & Mobile App Development for Wildlife Content Producer
Modular content & automated versioning
Content is increasingly assembled from reusable blocks—video segments, audio, captions, graphics—then re-versioned across CTV, mobile, and social outputs. OEM impact: you’ll be asked to support metadata-first pipelines, version-aware processing, and automation-friendly integration points.
Trusted media & deepfake protection
As AI-generated content becomes easier to produce and harder to verify, the demand for provenance, watermarking readiness, and real-time integrity checks will rise—especially in news, sports, and premium content. This trend is also reflected in broader ISE discussions about AI and cybersecurity in 2026.
OEM takeaway: design your pipeline so trust controls can be added without redesigning the entire platform.
How we typically engage (and why OEMs like this model)
OEM programs can fail for predictable reasons: unclear performance budgets, integration surprises, and late-stage rework. Our typical engagement model is built to de-risk delivery:
- Architecture & constraints: define throughput, latency, timing, interoperability, and update strategy.
- PoC / pilot: validate the hardest parts early (ST 2110/NMOS behavior, latency under load, AI module integration).
- Implementation: FPGA/video processing, embedded Linux/firmware, IP transport optimization, cloud modules where needed.
- Verification & production support: system-level testing, manufacturing readiness, and post-launch evolution.
The goal is simple: help OEM teams ship platforms where hardware, embedded software, and real-time networking work as one.
A 90-day action checklist for OEM roadmaps
If you want a practical starting point (without rewriting your whole product line), here’s what I recommend doing in the next 90 days:
- Define your latency budget end-to-end and decide how you will measure it under load.
- Set interoperability targets: which ST 2110 profiles, which NMOS behaviors, and what “done” means for commissioning.
- Decide where AI lives (edge/on-prem/cloud) for your top 1–2 automation use cases (analytics, QC, captions, compliance).
- Plan OTA + observability: product lifecycle is part of the value proposition now, not an afterthought.
- Pick one PoC that de-risks your roadmap: SDI→IP migration slice, low-latency transport path, or an AI-assisted module.
Book a 24h Expert Call / Architecture Review and we’ll map the shortest path to interoperability, lower latency, and AI-ready pipelines.
Our Case Studies







