

AI Model Training for Driver Monitoring and Behavior Detection
Project in Nutshell: сommissioned by a road safety solutions provider, we trained a neural model for a camera that detects mobile phone use and smoking.
Our engineers used a dataset of 12+ thousand images for YOLO, an open-source machine-learning model, to create an AI-powered camera software for driver monitoring solutions and other possible applications: critical infrastructure sites and smoke-free environments.
Client & Challenge
A road safety solution provider approached us to use machine learning and train a neuromodel to identify inappropriate driver behaviour that can lead to dangerous situations: smoking and talking on a mobile phone.
Solution
To implement the client's project, we formed a team of a data scientist, a firmware programmer, a QA engineer and a project manager.
We used an object detection approach with 2 classes. For driver behaviour analysis and distraction detection, we created our own dataset of 12+ thousand images; and in 8 months, we trained a neural model for the client using three YOLO family models — 5, 7, and 8 versions. The best result for unwanted behaviour detection was 88% with YOLov8.
Data Collection
Our engineers generated the dataset for training the neuromodel from several open-source datasets:
- COCO dataset: we selected about 2000 photos, excluding unsuitable ones: photos of button phones and phones without a caller. The task of the neural network is to detect not just a phone, but also a person calling.
- Open-source datasets: we also selected more than 3500 contextually appropriate photos.
We annotated the raw data using object detectors:
- YOLOv7, which was pre-trained to recognise phones on the COCO dataset;
- YOLOv4, trained to recognise cigarettes.
All photos were manually checked for annotation quality.
We have also selected and tested about 3000 photos without cigarettes and phones. This procedure improves the training efficiency and helps to avoid overtraining the model.
The final dataset contained 12522 images with:
- 9140 with pictures of phones and cigarettes, i.e. labelled images;
- 3382 unlabeled images.
The final dataset: 10991 images of a training subset and 1531 images of a validation subset.
Training Process
To train the neural network, we used several models of the YOLO family: YOLOv7, YOLOv8 and YOLOv5. We tested different training strategies: image size, custom additions, and custom anchors. We will describe the most stable configurations below.
Our team used mAP or mean average precision (mAP) as a metric for accuracy assessment, which is an analogue of accuracy in classification tasks. Precision measures your predictions' accuracy, and recall measures how well you find all the positives.
mAP.5 means that mAP is calculated at 0.5 intersection over union (IoU), and mAP.5.95 means average mAP, which is calculated at different IoUs in 0.05 increments.
YOLOv7 is a state-of-the-art model that has various features to achieve the best training results, such as optimal transport assignment method (OTA), mosaic augmentation, and others.
First of all, we experimented with training image size and got the best training progress using 640x640 px images. However, we eventually abandoned this image size in favour of 320x320 px images due to some problems:
- Slow training. Training on 640x640 images is almost 4 times slower than training on 320x320.
- Slow inference phase. Inference on 640x640 images is 4 times slower than on 320x320. 640x640 images are not suitable for real-time inference on embedded devices.
Other experiments with augmentations (excluding mosaic augmentation) and custom anchors resulted with overfitting and unstable training respectively.
The YOLOv7 model was trained for 700 epochs with a result of 75% mAP 0.5:
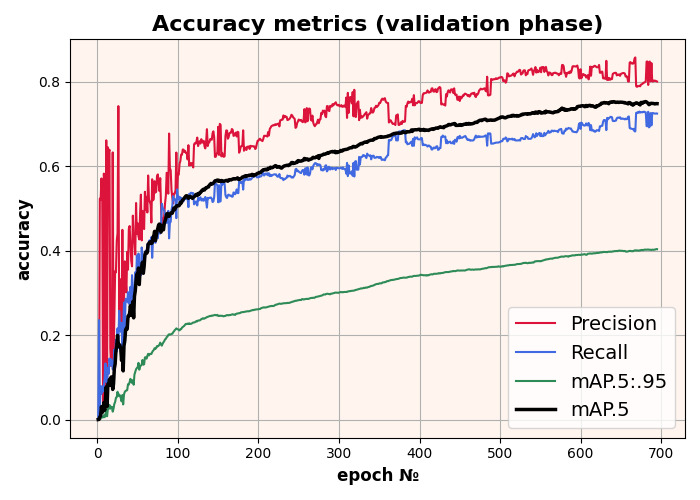
Training results of the YOLOv7 model
We trained the YOLOv8 model for 50 epochs on 640x640 input images, starting with the pre-trained COCO model. Best mAP is 0.88 at 0.5 scale.
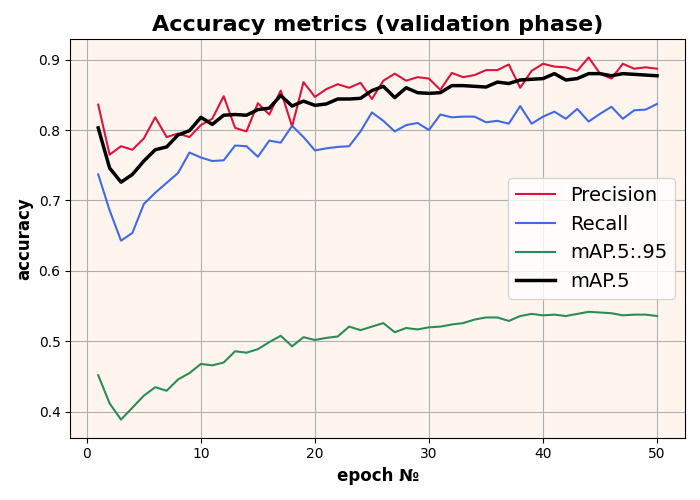
Training results of the YOLOv8 model
We used the YOLOv5 model in this project to experiment with optimisation and to compare it with the 7th and 8th versions. The YOLOv5 has its advantages: speed and simplicity. In addition, it has SiLU activation features that are not supported by many embedded devices. Therefore, all SiLU activations were replaced by ReLU activations.
The model was trained on 320x320 input images. The best mAP is 0.82 at 0.5 scale.
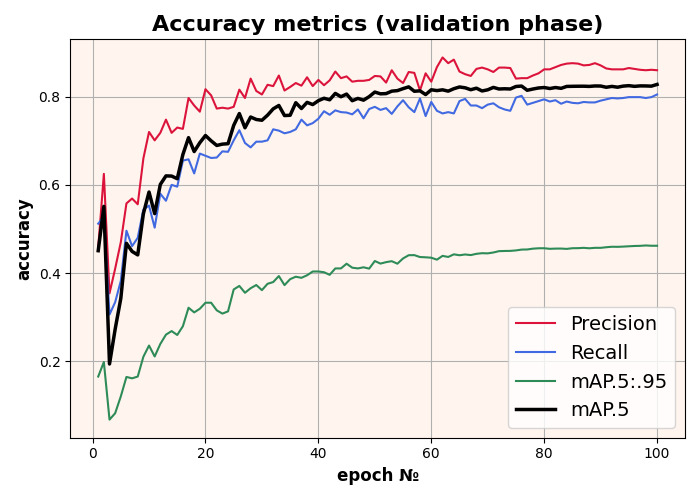
Training results of the YOLOv5 model
After training, we optimised the YOLOv5 model using the weights pruning approach. It allows us to identify and exclude weights that have insignificant influence. After this, the new model is fine-tuned to compensate for excluded weights. This procedure can be repeated several times.
There are various weights pruning approaches:
- Unstructured pruning does not consider the entire architecture, and prunes weights only by their own influence. This approach is inefficient because it does not reduce the model architecture — zero weights are also stored in memory — and does not affect the model output time.
- Structured pruning attempts to consider the entire architecture and exclude not only the weights but also the feature maps. This reduces the model architecture and hence reduces the model inference time.
In this project, we used structured pruning and pruned YOLOv5 twice. The first time, we pruned with 0.4 sparsity, i.e. we excluded about 40% of the model and fine-tuned it on the same dataset. The second time, the model was pruned with 0.5 sparsity and fine-tuned again.
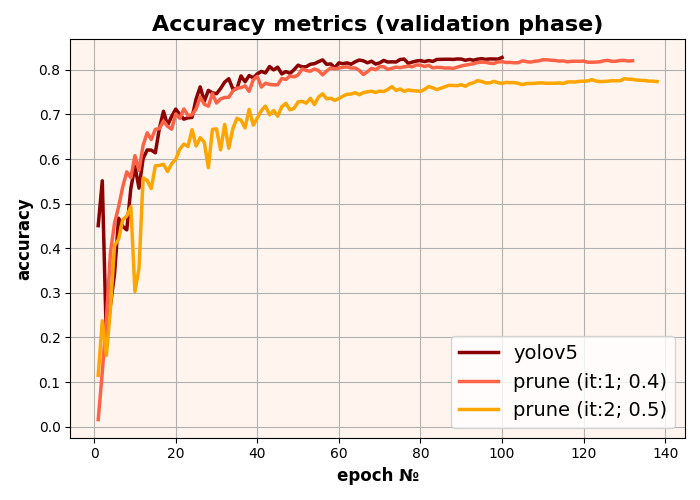
YOLOv5 model pruning results
The training results of all models are shown in the graph below. The best result was achieved when training the YOLOv8 model — 88% accuracy.
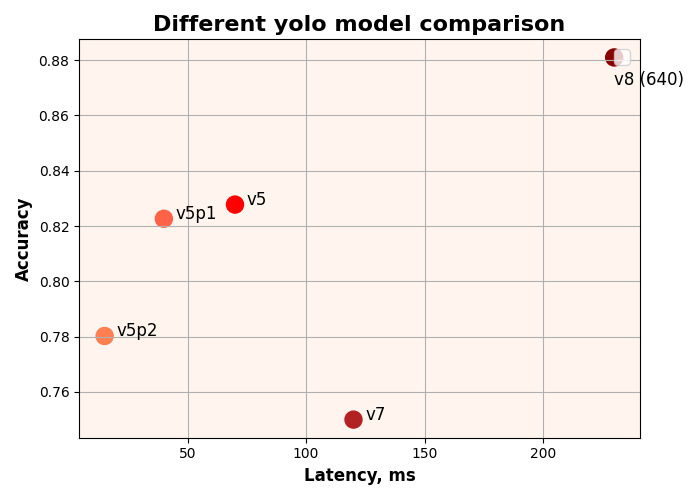
Comparison of the training results for all the YOLO models
Business Value
The introduction of a neural model capable of distinguishing between smoking and talking on a mobile phone will improve our client's existing driver monitoring solutions and make driving even safer.
Cameras that detect mobile phone use and smoking can be installed in other locations:

1. Critical infrastructure facilities such as power plants or chemical plants, where smoking is often prohibited for safety reasons.

2. Workplaces where smoking is prohibited or where the use of mobile phones distracts from work and creates a safety hazard.

3. Public places where there is a need to provide a smoke-free environment: shopping centres, airports, concert halls, stadiums, educational institutions, etc.







































